Miso, Meltano and Setting Up Real-Time, Continuous Personalization

As a real-time personalization data platform (PDP), Miso relies solely on two key first-party data inputs to generate real-time, continuous, dynamic, in-session personalization. The first data input are your user clickstream logs, which reflect the key actions and events each individual user is driving on your site or app, and which should be provided in real-time. The second data input is your product catalog, which ideally are being updated in real-time as well, especially if you’re a marketplace or user-generated content site, or at least updated continuously on a regular cron job schedule.
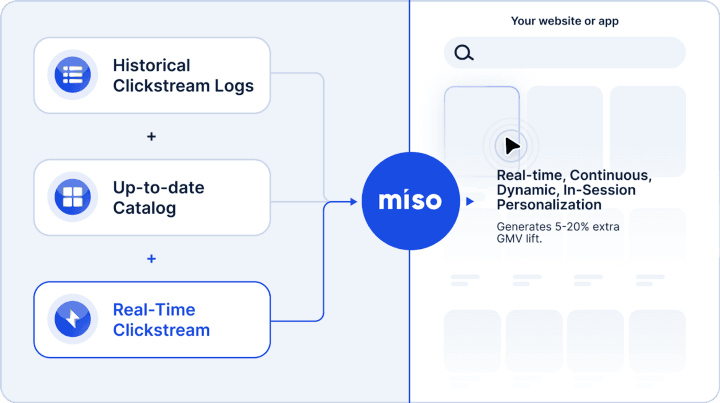
As a team who built personalized platforms for a living before Miso, we’re very sympathetic to the lift this entails. And not only have we built out a range of integrations to streamline getting started, we make sure we’re available 24/7 for our partners, over Slack and Zoom, to help debug and support each of them on best practices every step of the way.
Since joining the Miso Shiba Squad a year ago, as a DevX Engineer, I’ve gotten the opportunity to talk to many teams across different domains and, of course, infrastructure variation about their process of integrating Miso into their tech stack. At its core, Miso is an API-first platform, which by its nature allows for a lot of implementation flexibility and creative data integration solutions. One interesting implementation pattern that I’ve seen teams use repeatedly is using a combination of Miso’s client-side SDK for streaming in their real-time clickstream logs and a reverse-ETL (or ELT) tool like Meltano to enable near real-time catalog updates, plus the first historical data bulk uploads from their clickstream warehouse.
We’ve talked about using the Miso’s client-side SDK in a previous article, so now let’s take a closer look at Meltano.
Meltano is an open-source ELT platform whose development is sponsored by GitLab (another amazing open-source DevOps platform that we use here at Miso.ai). The folks at Meltano believe in the commoditization of data integration, which is evident in the hundreds of data plug-ins that are supported by their open-source community. Miso participates in the Meltano ecosystem via target-miso, a singer-based data loader that can push data to Miso’s personalization platform.
We’re of course not suggesting that you have to use Meltano to be able to integrate with Miso — but it is a great open-source solution that plays well with Miso. There are other, similar products in this space like Hightouch, Meroxa, and Apache Airflow and stay tuned for more posts on those as well. Our engineering team is constantly building out new toolings for the wider ecosystem of databases, data warehouses, and ETL/ELT systems out there.
Miso Meets Meltano

Miso’s search and recommendation engines are trained and tuned on your product catalog and user clickstream data. This allows our predictive data models to perform multivariate, embedding-based clustering (which maps users and products in the same vector space) to output a ranked list of products that are most likely aligned with the behavioral intent of a given user.
While the initial, historical data dump to kick off the engine training is pretty trivial, orchestrating a productionizable data pipeline for future product updates can be tricky, especially if you’re the one tasked with maintaining a data extractor.
This is where Meltano can fit right into your data stack. At the most basic level, you choose a data source (or tap) and a destination (target-miso) and Meltano, with the help of Singer — an open-source data exchange format — that will take care of the software glue in between. Here’s a good introduction to Singer.io
An important caveat is that Meltano is not real-time. It can be scheduled to refresh as often as you’d like, even on a near real-time basis, but there’s no way to natively set up Meltano to trigger as soon as data is generated. That’s why we recommend only using Meltano for sending catalog updates (as near real-time updates are sufficient) or optional user demographic data or preference data (for instance, if you have quizlets in your app or purchase flow).
Let’s look at a concrete example. Suppose your product catalog lives in a Postgres database. Your merchandising and (physical) product team adds new SKUs every week and you want to make sure that Miso’s engines are receiving those updates and recommending new products to customers (fun fact: we excel at this type of product cold-start problem). There should be a pipeline in place to reliably extract the data from postgres and load it into Miso. You could probably build it from scratch, especially given our API-first approach and the suite of Data APIs we offer, but there’s value to not reinventing the wheel when a vetted open-source solution in Meltano is available.
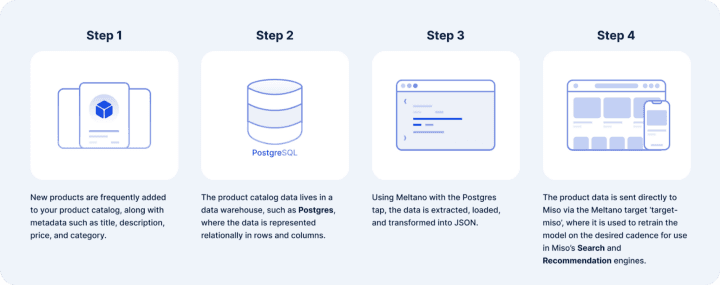
BTW, what the heck is Singer?
Meltano is built on top of an open-source framework called Singer.
Some of the best things in life are singers. From legendary sewing machines that never die, to resto-modded Porsche 911s, to The Masked Singer (depends on the singer), it’s no surprise that Singer.io is the open-source standard for writing scripts that move data.
Singer defines two types of scripts: extractors (which are called taps) and loaders (which are called targets). Taps and targets are the things that do the moving. As an example, using simple CLI commands like “tap-salesforce | target-csv” moves data from salesforce into a csv file. The best part is that Singer is open-source and continuously getting updates from the community. Here’s a look at some of the taps and targets that Singer (and by extension Meltano) currently supports.

The thing that Singer purports to do — the moving data thing — it does really well. But it’s barebones otherwise and missing the testing, orchestration, and deployment features that organizations need before they can comfortably productionize a data pipeline. That’s where Meltano comes in.
For more information on Singer, here’s a useful getting started guide.
Setting up a data pipeline using Meltano
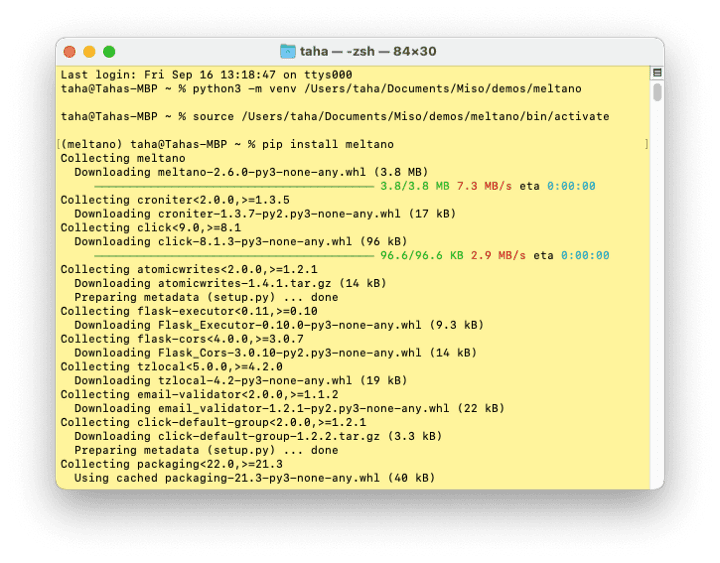
Installing the Meltano framework
The official Meltano guide does a great job of guiding you through the framework installation process. One requirement is that you will need to have Python 3 installed. The example I’ll be providing is based on UNIX commands but the official guide also has a Windows-specific implementation.
First, let’s create a virtual python environment, activate it, and install the Meltano package.
Initializing a Meltano project
Next, we’ll create and navigate to a new directory that will hold our Meltano project and initialize it. We’ll call the project “postgres-demo”. This will create three environments: dev, test, and prod, as well as a meltano.yml file that will hold the details of our tap and target.
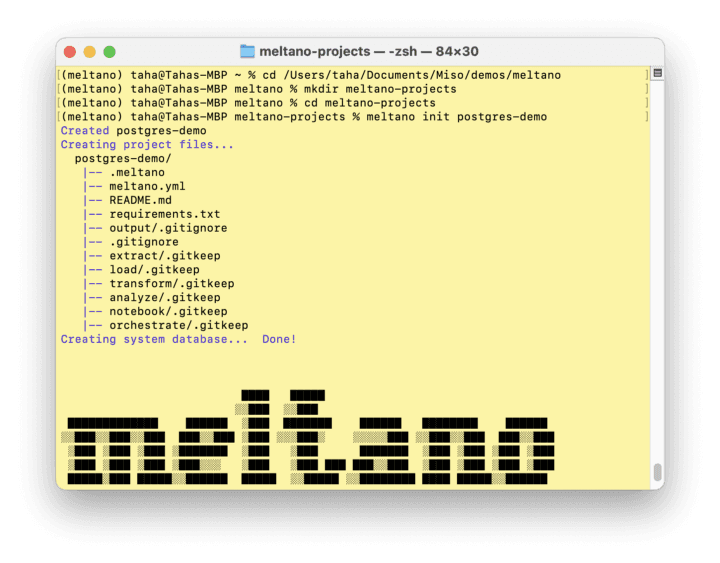
Choosing an extractor and loader
As I mentioned earlier, our example is moving data from a postgres database to Miso. Therefore, our extractor is postgres and our loader is Miso. We need to add in these details inside the meltano.yml file that was automatically created when we initialized the meltano project in the previous step.
Meltano provides a great overview of all the intricacies and nuances of configuring the meltano.yml file so we won’t get into the details here, but at the most basic level, it should look something like this:
version:1
default_environment: dev
project_id: d347016d-0d0d-4110-a0ad-cf7e516f76a2
plugins:
extractors:
- name: tap-postgres
executable: tap-postgres
variant: transferwise
pip_url: pipelinewise-tap-postgres
config:
host: $PG_HOST
port: $PG_PORT
user: $PG_USER
password: $PG_PASSWORD
dbname: $PG_DBNAME
select:
- public-users.*
metadata:
public-users:
replication-method: INCREMENTAL
replication-key: create_time
loaders:
- name: target-miso
namespace: target_miso
pip_url: target-miso
executable: target-miso
config:
template_folder: template
api_server: $MISO_API_SERVER
api_key: $MISO_API_KEY
use_async: false
environments:
- name: dev
Note that the connection settings should be stored in a separate environment file.
Whoops…we don’t actually have any data yet.
Let’s fix that by creating some dummy user data inside a postgres database. If you want to follow along, I’m using this SQL file and this shell script to create 100 random users, along with some demographic information.
Note: Not to distract from this walkthrough…but demographic data isn’t a key thing to ever send Miso. In fact, we ask teams never to send us any PII. And usually if demographic data is sent to Miso, it’s hashed. But I digress.
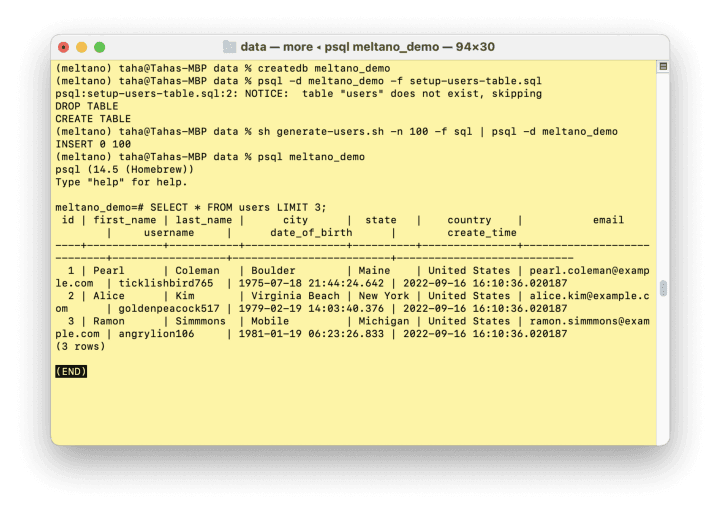
Mapping the data using a template
So now that we have user data in a SQL table, we are really close to sending it over to Miso. The final preparatory step is to define a template that maps the SQL schema to a JSON structure that Miso can accept as an API payload. To do this, create a directory called “template” in your project folder and create a .jinja file inside that looks like this:
{
"user_id": "{{ data.id }}",
"city": "{{ data.city }}",
"state": "{{ data.state }}",
"country": "{{ data.country }}",
"name": "{{ data.first_name }} {{ data.last_name }}",
"custom_attributes": {
"username": "{{ data.username }}",
"email": "{{ data.email if data.email }}",
"date_of_birth": "{{ data.date_of_birth | datetime_format }}",
"create_time": "{{ data.create_time | datetime_format }}"
}
}
With this template, we are telling Meltano which fields in the users table map to which JSON fields in the payload. This should be the same structure as our Users API.
Let’s see if it works
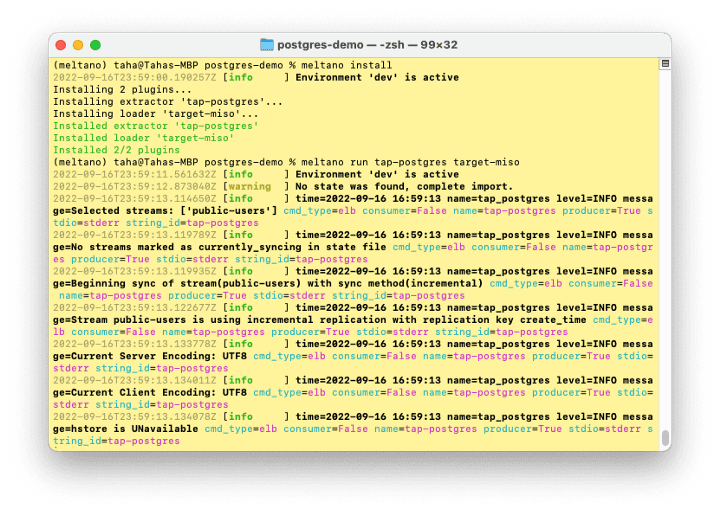
Using the command “meltano run tap-postgres target-miso” we sent the data from our local Postgres database to Miso. Let’s check our data in Dojo:
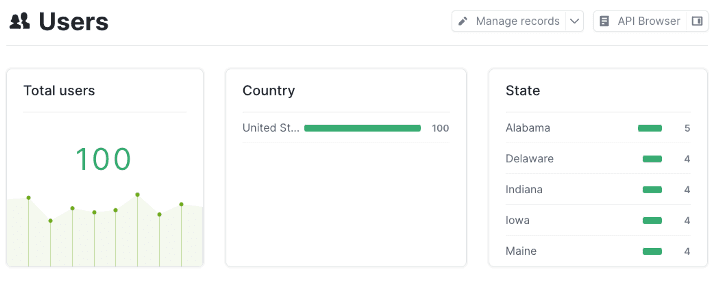
Looks like all 100 users made it over! Small note that while this example used a mock user dataset, Miso doesn’t actually require separate user data at all. User profiles are optional at this point. We instead rely on interaction and product catalog data, both of which are just as easy to send using Meltano. The only thing that would need to be changed is the template file.
And although we didn’t get into the specifics in this post, Meltano has a ton of cool features to check out, like orchestration, containerization, and discovery mode.
Deep Thoughts with Taha
If open source is more your style, Meltano is a great option for an ELT pipeline solution. Admittedly, this integration does take a fair bit of configuration upfront, especially since you need to map the schema from your source to a JSON destination format that Miso can ingest. On the flip side, the manual configuration means that there is a ton of configuration flexibility and options to explore. If you’re not super comfortable with working via the CLI, there’s also a browser-based Meltano UI available to use, though it’s not as comprehensive. As I mentioned earlier, Meltano on its own for your catalog and clickstream events will get you to static, 1:1 personalization, but to really get to the next level and have real-time personalization that’s optimized for coldstart visitors and in-session personalizations for all users, really, you’ll need to also pipeline real-time clickstream data. A great option for doing that is using our client-side SDK for JavaScript.
Before I close out, I’d like to give a shoutout to Lucky Gunasekara and Lan Le for their editing expertise and Stian Johannessen for his design work. If there’s an integration (or any other topic, really) that you’re curious about and want us to unpack, drop us a line on our contact form or at hello@askmiso.com. We’d love to hear about what you’re working on and how we can help!
